强化学习的核心思想是通过Agent与环境的不断交互,以最大化累计回报为目标来选择合理的行动,这与人类智能中经验知识获取和决策过程不谋而合。特别是近年来深度强化学习在以AlphaGo、AlphaZero、AlphaStar等为代表的机器智能领域的突破,进一步展现了强化学习在解决复杂决策问题的能力,成为人工智能研究领域的热点。
当前强化学习主要研究的方法可以分为3类:基于值函数的强化学习方法、基于策略搜索的强化学习方法和基于环境建模的强化学习方法。
基于价值的强化学习模型和基于策略的强化学习模型都不是基于模型的,它们从价值函数,策略函数中直接去学习,不用学习环境的状态转化概率模型,即在状态s下采取动作a,转到下一个状态s’的概率P
而基于模型的强化学习则会尝试从环境的模型去学习,一般是下面两个相互独立的模型:一个是状态转化预测模型,输入当前状态s和动作a,预测下一个状态s’。另一个是奖励预测模型,输入当前状态s和动作a,预测环境的奖励r。即模型可以描述为下面两个式子:
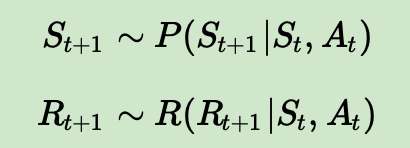
如果模型P,R可以准确的描述真正的环境的转化模型,那么我们就可以基于模型来预测,当有一个新的状态S和动作A到来时,我们可以直接基于模型预测得到新的状态和动作奖励,不需要和环境交互。当然如果我们的模型不好,那么基于模型预测的新状态和动作奖励可能错的离谱。基于模型的强化学习算法训练流程,其流程和我们监督学习算法是非常类似的。
虽然基于模型的强化学习思路很清晰,而且还有不要和环境持续交互优化的优点,但是用于实际产品还是有很多差距的。主要是我们的模型绝大多数时候不能准确的描述真正的环境的转化模型,那么使用基于模型的强化学习算法得到的解大多数时候也不是很实用。那么是不是基于模型的强化学习就不能用了呢?也不是,我们可以将基于模型的强化学习和不基于模型的强化学习集合起来,取长补短,这样做最常见的就是Dyna算法框架。

