首页
PyTorch官网
PyTorch pip安装
PyTorch whl安装
CUDA安装
cuDNN安装
GPU并行训练
PyTorch官方入门
PyTorch API学习
PyTorch Lightning
PyG官方入门
PyTorch精品教程
Tensor维度详解
PyTorch计算图
梯度下降法
PyTorch Adam
梯度装饰器
电子书与软件
AI数学电子书
希腊字母列表
AI作图工具
LaTex入门教程
LaTex常用命令
LaTex在线编辑器
AI实习岗招聘
AI面试十大考点
飞燕AI训练营
关于网站
本站社群
AI自媒体
AI外包
无人机实战
分类
强化学习电子书
下的文章
《深度学习入门4:强化学习》高清完整PDF版 下载
撰写于:
2024-09-22
浏览:1885 次 分类:
强化学习电子书
1、封面介绍2、出版时间2024年8月3、内容介绍本书系统介绍了基于强化学习的多智能体协同技术,涉及进化算法、纳什均衡等相关主题,讨论了基于强化学习的多智能体协同理论、一致性学习算法、基于协同Q学习算法的多智能体规划技术等,并给出了针对多机器人协同问题的应用实例。本书不仅包含多智能体强化学习协同研究的最新进展,而且提供了一种相对于传统方法更加高效的[...]
《多智能体协同:强化学习方法》高清完整PDF版 下载
撰写于:
2024-09-22
浏览:473 次 分类:
强化学习电子书
1、封面介绍2、出版时间2022年7月3、内容介绍本书系统介绍了基于强化学习的多智能体协同技术,涉及进化算法、纳什均衡等相关主题,讨论了基于强化学习的多智能体协同理论、一致性学习算法、基于协同Q学习算法的多智能体规划技术等,并给出了针对多机器人协同问题的应用实例。本书不仅包含多智能体强化学习协同研究的最新进展,而且提供了一种相对于传统方法更加高效的[...]
《深度强化学习图解》高清完整PDF版 下载
撰写于:
2024-09-22
浏览:794 次 分类:
强化学习电子书
1、封面介绍2、出版时间2022年7月3、内容介绍我们在与环境交互的过程中进行学习,经历的奖励或惩罚将指导我们未来的行为。深度强化学习将该过程引入人工智能领域,通过分析结果来寻找最有效的前进方式。DRL智能体可提升营销效果、预测股票涨跌,甚至击败围棋高手和国际象棋大师。《深度强化学习图解》呈现生动示例,指导你构建深度学习体系。Python代码包含详[...]
《深度强化学习》高清完整PDF版 下载
撰写于:
2024-09-22
浏览:437 次 分类:
强化学习电子书
1、封面介绍2、出版时间2024年6月3、内容介绍近年来,深度强化学习成为关注的热点。在自动驾驶、棋牌游戏、分子重排和机器人等领域,计算机程序能够通过强化学习,理解以前被视为超级困难的问题,取得了令人瞩目的成果。在围棋比赛中,AlphaGo接连战胜樊麾、李世石和柯洁等人类冠军。深度强化学习从生物学和心理学领域的研究中受到启发。生物学激发了人工神经网[...]
基于环境建模的强化学习方法
撰写于:
2024-09-06
浏览:403 次 分类:
强化学习电子书
强化学习的核心思想是通过Agent与环境的不断交互,以最大化累计回报为目标来选择合理的行动,这与人类智能中经验知识获取和决策过程不谋而合。特别是近年来深度强化学习在以AlphaGo、AlphaZero、AlphaStar等为代表的机器智能领域的突破,进一步展现了强化学习在解决复杂决策问题的能力,成为人工智能研究领域的热点。当前强化学习主要研究的方法[...]
Pop-Art算法详细介绍
撰写于:
2024-07-14
浏览:642 次 分类:
强化学习电子书
Pop与Art分别表示Preserving Outputs Percisely以及Adaptive Rescaling Target, 即在保障已历经样本输出不变的前提下自适应缩放target值的算法。这个算法来自文献:《Multi-task Deep Reinforcement Learning with popart》。PopArt这个算法本来[...]
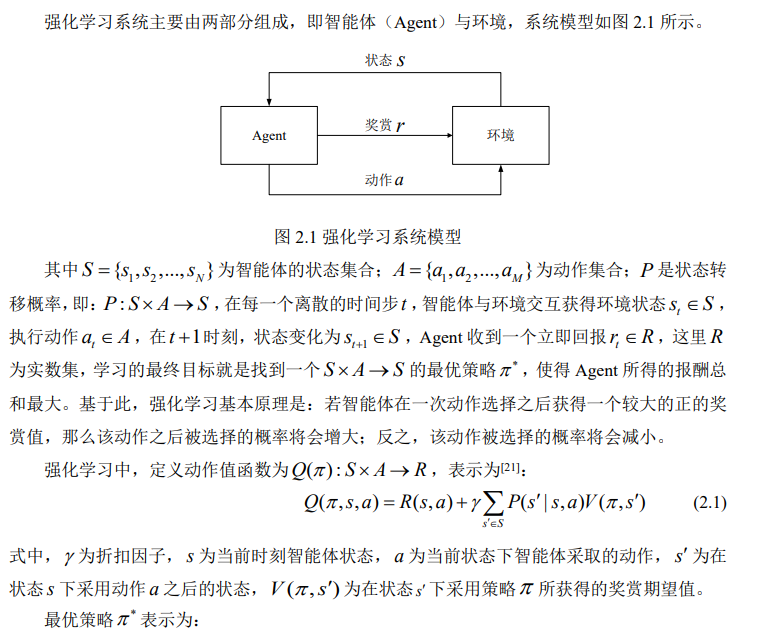
强化学习基本原理
撰写于:
2023-07-01
浏览:964 次 分类:
强化学习电子书
Q-learning 算法介绍
撰写于:
2023-06-29
浏览:996 次 分类:
强化学习电子书
Q-Learning是强化学习中的最基础算法,它基于Q-Table来实现。这个表格的每一行都代表着一个状态(state),每一行的每一列都代表着一个动作(action),而每个值就代表着如果在该state下采取该action所能获取的最大的未来期望奖励。通过Q-Table就可以找到每个状态下的最优行为,进而通过找到所有的最优action来最终得到最[...]
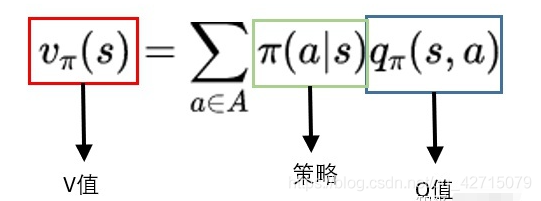
深刻理解强化学习中的Q值和V值
撰写于:
2023-06-29
浏览:1051 次 分类:
强化学习电子书
在马尔可夫决策过程中,当智能体从一个状态S,选择动作A,会进入另外一个状态S'。同时,也会给智能体奖励R。 奖励既有正,也有负,正代表我们鼓励智能体在这个状态下继续这么做,负得话代表我们并不希望智能体这么做。 在强化学习中,我们会用奖励R作为智能体学习的引导,期望智能体获得尽可能多的奖励。需要注意的是:很多时候,我们并不能单纯通过R来衡量一个动作的[...]
protobuf 版本问题:Downgrade the protobuf package to 3.20.x or lower.
撰写于:
2023-05-22
浏览:5219 次 分类:
强化学习电子书
1、Protobuf 简介Protocol Buffers(简称 Protobuf),是Google公司开发的一种数据描述语言,类似于XML能够将结构化数据序列化,可用于数据存储、数据交换、通信协议等方面。相比于它的前辈XML、Json,它的体量更小,解析速度更快,所以在业内获得了广泛的应用。在多智能体强化学习过程中,由于多个Agent位于不同的节[...]
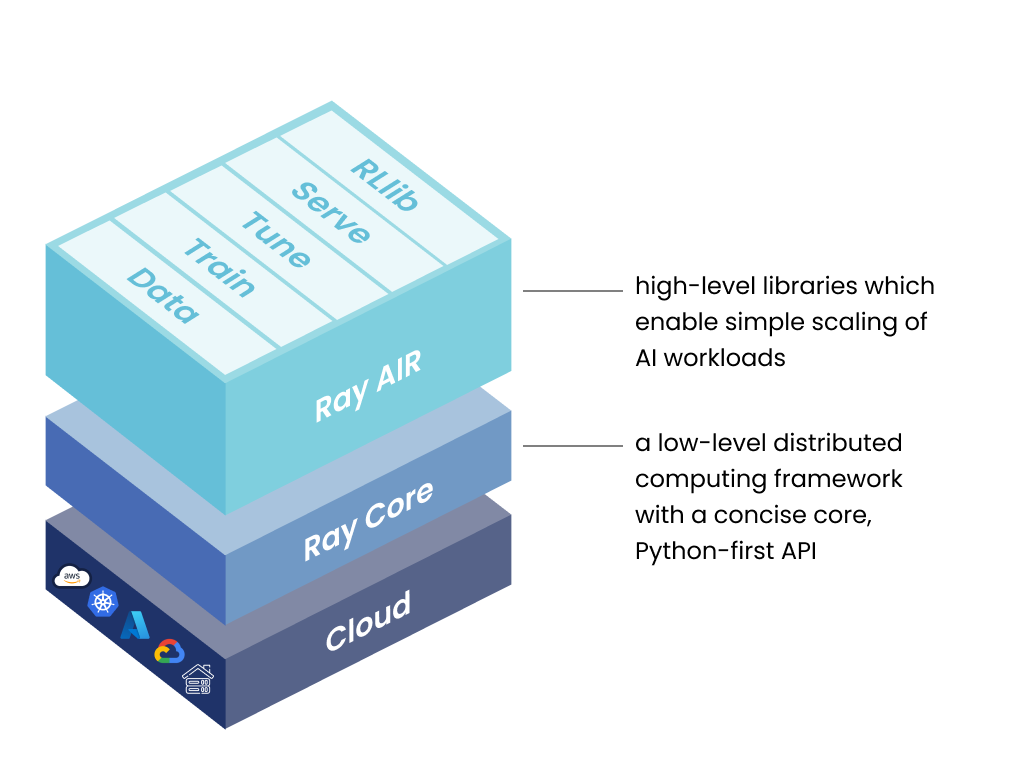
分布式框架Ray详细介绍
撰写于:
2023-05-21
浏览:1766 次 分类:
强化学习电子书
Ray简介Ray是一个开源的人工智能分布式框架,它的目标是让开发者仅需添加数行代码就能轻松转为适合于计算机集群运行的高性能分布式应用。今天的深度学习越来越需要计算资源,像笔记本电脑这样的单节点开发环境无法扩展以满足算力需求,Ray是将Python和AI应用程序从笔记本电脑扩展到集群的统一方法。使用Ray,您可以将相同的代码从笔记本电脑无缝扩展到集群[...]
强化学习中REINFORCE算法详细介绍
撰写于:
2023-05-20
浏览:1239 次 分类:
强化学习电子书
REINFORCE介绍强化学习中的策略优化主要有两类:基于价值的方法和基于策略的方法(当然两者的结合产生了 Actor-Critic 等算法)。基于值函数的方法主要是学习值函数,然后根据值函数导出一个策略,学习过程中并不存在一个显式的策略;而基于策略的方法则是直接显式地学习一个目标策略。基于价值的方法主要有DQN,而基于策略的方法有REINFORC[...]
value-based和policy-based的区别是什么?
撰写于:
2023-05-20
浏览:1864 次 分类:
强化学习电子书
强化学习中的策略优化主要有两类:基于value价值的方法和基于policy策略的方法(当然两者的结合产生了 Actor-Critic 等算法)。基于值函数的方法主要是学习值函数,然后根据值函数导出一个策略,学习过程中并不存在一个显式的策略;而基于策略的方法则是直接显式地学习一个目标策略。value-based方法是先通过计算出值函数,然后再求策略;[...]
马尔可夫决策过程(MDP)是什么?
撰写于:
2023-05-19
浏览:853 次 分类:
强化学习电子书
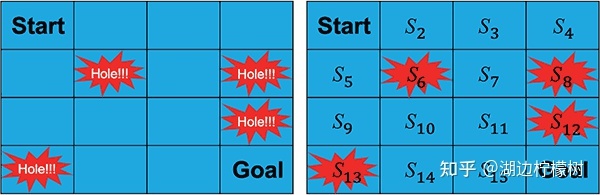
马尔可夫决策过程简介马尔可夫决策过程(Markov Decision Processes,MDP)是对强化学习中环境的形式化的描述,或者说是对于智能体所处的环境的一个建模。在强化学习中,几乎所有的问题都可以形式化地表示为一个马尔可夫决策过程。本文以Frozen Lake游戏为例,介绍一下马尔可夫决策过程。Frozen Lake 游戏介绍Frozen[...]
env.unwrapped 的作用
撰写于:
2023-05-18
浏览:1260 次 分类:
强化学习电子书
当我们使用gym创建环境的时候:env = gym.make('CartPole-v0')返回的env其实并非CartPole类本身,而是一个经过包装的环境。包装的过程可以看这里:def make(self, path, **kwargs): spec = self.spec(path) env = spec.m[...]
1
2
3
关注公众号,了解站长最新动态
分类
默认分类
PyTorch 电子书
Python 电子书
推荐系统电子书
计算机视觉电子书
机器学习电子书
强化学习电子书
PyTorch 教程
AI数学电子书
数据结构与算法电子书
人工智能实习与内推
网站公告
图神经网络电子书
飞燕AI训练营
多智能体与无人机
科研论文
大模型电子书
创业杂谈
PyTorch GPU 并行训练
PyTorch Lightning 使用介绍
睡前数学APP
最新文章
L1范数倾向于产生稀疏解
L1范数倾向于产生稀疏解的举例说明
torch.max的详细介绍
L1范数的作用是什么?
欧几里得范数是什么?它有什么用?
向量的范式是什么?它有什么用?
torch.norm的详细介绍与使用举例
torch.frombuffer的详细介绍
torch.tensor()和torch.as_tensor()的区别是什么?
torch.asarray和torch.as_tensor的区别是什么?
torch.asarray的详细介绍
torch.polar的详细介绍
torch.heaviside的详细介绍
torch.logspace的详细介绍
torch.linspace的详细介绍
热门文章
《 百面深度学习》高清完整PDF版 下载
《深度学习推荐系统》全彩版 高清完整PDF版 下载
《Python深度学习:基于PyTorch》中文版 高清完整PDF版 下载
技术交流群-成员昵称-参考列表
《机器学习的数学》高清完整PDF版 下载
2025年2月网站资源下载公告
《优美的数学思维(原书第2版)》高清完整PDF版 下载
Keras怎么读?解读Keras英文发音
最新评论
瑾年
:
非常好的书
阿瑶
:
求书
xxxx
:
谢谢
安全科学家
:
请赐教,谢谢
matt
:
非常值得推荐
晒衣你
:
好书
半缘君
:
个人学习用,谢谢支持
xiaobai
:
大佬,可以麻烦您发我[...]
bodong
:
感谢分享
Ruozi
:
非常好的书
友情链接