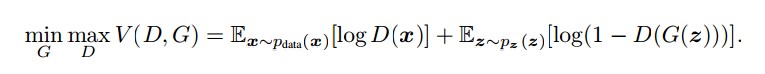首页
PyTorch官网
PyTorch pip安装
PyTorch whl安装
CUDA安装
cuDNN安装
GPU并行训练
PyTorch官方入门
PyTorch API学习
PyTorch Lightning
PyG官方入门
PyTorch精品教程
Tensor维度详解
PyTorch计算图
梯度下降法
PyTorch Adam
梯度装饰器
电子书与软件
AI数学电子书
希腊字母列表
AI作图工具
LaTex入门教程
LaTex常用命令
LaTex在线编辑器
AI实习岗招聘
AI面试十大考点
飞燕AI训练营
关于网站
本站社群
AI自媒体
AI外包
无人机实战
默认分类
《图解人工智能》高清完整PDF版 下载
撰写于:
2021-10-27
浏览:2369 次 分类:
默认分类
1、封面介绍2、出版时间2021年4月3、推荐理由近年,人工智能热潮席卷而来。本书以图解的方式网罗了人工智能开发的基础知识,内容涉及机器学习、深度学习、强化学习、图像和语音的模式识别、自然语言处理、分布式计算等热门技术。全书以图配文,深入浅出,是一本兼顾理论和技术的人工智能入门教材。旨在帮助读者建立对人工智能技术的整体印象,为今后深入探索该领域打下[...]
默认分类
《人工智能通识课》高清完整PDF版 下载
撰写于:
2021-10-27
浏览:3264 次 分类:
默认分类
1、封面介绍2、出版时间2021年6月3、推荐理由《人工智能通识课》纵贯人工智能技术在全球 70 多年的发展历史,综合逻辑学派和神经网络学派的主流观点,系统介绍了人工智能各种算法的起源与演进过程,以及人工智能技术在消费者行为分析、机器人、自动驾驶、医疗等方面的应用实践,使读者可以全面了解人工智能领域的真实现状,及其给人类社会带来的技术、哲学乃至艺术[...]
默认分类
网站公告:关于本站电子书下载的新方式
撰写于:
2021-10-23
浏览:5869 次 分类:
默认分类
大家好,我是站长飞燕。本站上线数年有余,为技术爱好者无偿提供了若干PDF电子书,感谢大家的支持!来北京的最初几年时间里,住着租的房子,每次搬家的时候,面对着很多的书,我就有点发愁,扔的话有点舍不得,搬的话有点费事,当时我就想,这些书要是变成PDF电子书就好了。后来,买了房子,由于家离公司比较远,从丰台边角到软件园,路上差不多得花费2个小时,电子书就[...]
PyTorch 教程
调整学习率的利器:torch.optim.lr_scheduler
撰写于:
2021-06-24
浏览:1322 次 分类:
PyTorch 教程
lr_scheduler 简介torch.optim.lr_scheduler模块提供了一些根据epoch训练次数来调整学习率(learning rate)的方法。一般情况下我们会设置随着epoch的增大而逐渐减小学习率从而达到更好的训练效果。为什么需要调整学习率在深度学习训练过程中,最重要的参数就是学习率,通常来说,在整个训练过层中,学习率不会一[...]
PyTorch 教程
如何理解深度学习中的学习率?
撰写于:
2021-06-12
浏览:1641 次 分类:
PyTorch 教程
1、什么是学习率?学习率是指导我们在梯度下降法中,如何使用损失函数的梯度调整网络权重的超参数。其数学表达式如下所:new_weight = old_weight - learning_rate * gradient2、学习率的数学本质如上述公式,我们可以看到,学习率类似于微积分中的dx,所以学习率也被称为步长。3、学习率对损失值甚至深度网络的影响?[...]
PyTorch 教程
AdaGrad算法
撰写于:
2021-06-12
浏览:1241 次 分类:
PyTorch 教程
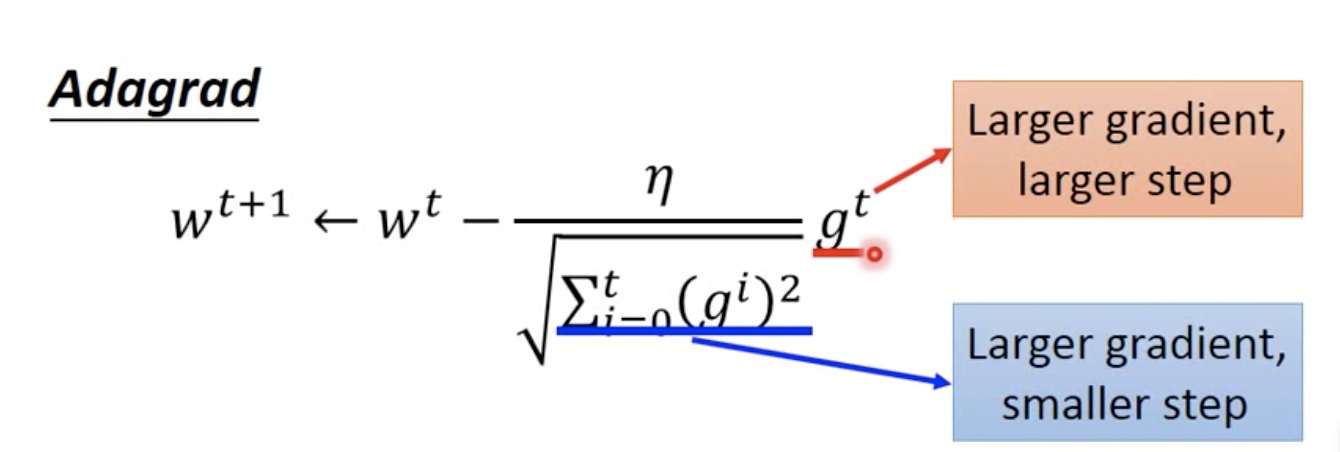
AdaGrad算法是什么?AdaGrad算法就是将每一个参数的每一次迭代的梯度取平方累加后在开方,用全局学习率除以这个数,作为学习率的动态更新。梯度下降算法、随机梯度下降算法(SGD)、小批量梯度下降算法(mini-batch SGD)、动量法(momentum)、Nesterov动量法有一个共同的特点是:对于每一个参数都用相同的学习率进行更新。但[...]
PyTorch 教程
AdaGrad:自适应梯度算法
撰写于:
2021-06-11
浏览:1262 次 分类:
PyTorch 教程
AdaGrad是解决不同参数应该使用不同的更新速率的问题。Adagrad自适应地为各个参数分配不同学习率的算法。其公式如下:但是我们发现一个现象,本来应该是随着gradient的增大,我们的学习率是希望增大的,也就是图中的gt;但是与此同时随着gradient的增大,我们的分母是在逐渐增大,也就对整体学习率是减少的,这是为什么呢?这是因为随着我们更[...]
PyTorch 教程
Adam优化器
撰写于:
2021-06-11
浏览:1041 次 分类:
PyTorch 教程
Adam优化器是深度学习中最流行的优化器之一。它适用于很多种问题,包括带稀疏或带噪声梯度的模型。其易于精调的特性使得它能够快速获得很好的结果,实际上,默认的参数配置通常就能实现很好的效果。Adam 优化器结合了 AdaGrad 和 RMSProp 的优点。Adam 对每个参数使用相同的学习率,并随着学习的进行而独立地适应。此外,Adam 是基于动量[...]
默认分类
向量简介
撰写于:
2021-06-07
浏览:1070 次 分类:
默认分类
什么是向量?在数学中,向量(也称为矢量),指具有大小和方向的量。向量可以形象化地表示为带箭头的线段。箭头所指代表向量的方向;线段长度代表向量的大小。与向量对应的量叫做标量,标量只有大小,没有方向。向量的表示法向量的记法1:黑体(粗体)的字母(如a、b、u、v),书写时在字母顶上加一小箭头“→”。 向量的记法2:如果给定向量的起点(A)和终点(B),[...]
默认分类
CUDA与cuDNN介绍
撰写于:
2021-05-18
浏览:1561 次 分类:
默认分类
最近带徒教人深度学习,中间碰到了很多基础知识,在备课的过程中,顺便自己也复习了一遍,深深体会到了“教学相长”的甜头。本文主要是给大家讲授一下关于CUDA与cuDNN方面的内容。1、什么是CUDACUDA全称是:ComputeUnified Device Architecture,是显卡厂商英伟达(NVIDIA)推出的运算平台。CUDA发布于2006[...]
默认分类
本站资源下载通道
撰写于:
2021-04-25
浏览:1872 次 分类:
默认分类
本站的所有资源均来源于互联网,来源于其他热心读者的提供,仅供个人学习,请勿挪作他用。最后提醒一下:请勿给站长发红包!谢谢大家的支持!本站资源下载通道是微信公众号,马上开启,敬请期待......
PyTorch 教程
GAN原理介绍
撰写于:
2021-03-15
浏览:1260 次 分类:
PyTorch 教程
1、GAN原理介绍生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。GAN出自[...]
默认分类
GNN方法在推荐系统领域的应用
撰写于:
2021-03-09
浏览:1416 次 分类:
默认分类
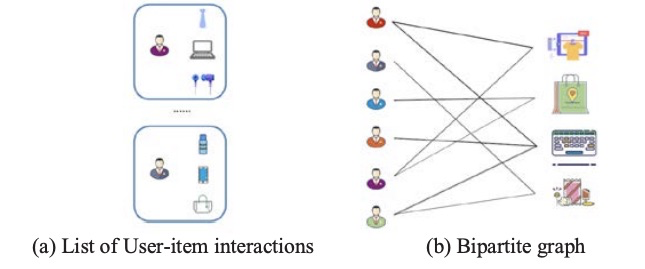
推荐系统会存储大量的用户与items交互数据,这些数据可以用二部图呈现。二部图对消除推荐系统中数据稀疏性和冷启动有着巨大的帮助。本文主要总结了3个典型的GNN方法在推荐系统领域处理用户与items的二部图。user-item二部图我们可以通过每个用户交互过的item列表,构建一个巨大的二部图,如下图所示:传统的神经网络方法(如协同过滤,双塔),是无[...]
默认分类
confidence weight 分类
撰写于:
2021-03-09
浏览:982 次 分类:
默认分类
通常情况下,confidence weight可以被分为三类:(1)Heuristic:典型的例子是加权的矩阵分解以及动态MF,未观测到的交互被赋予较低的权重。还有很多工作则基于用户的活跃度指定置信度等。但是赋予准确的置信权重是非常有挑战的,所以这块依然处理的不是非常好。(2)Sampling: 另一种解决曝光bias的方式就是采样,经常采用的采样[...]
推荐系统电子书
NLTK学习简介
撰写于:
2021-03-09
浏览:1152 次 分类:
推荐系统电子书
1、NLTK是什么?NLTK 全称"Natural Language Toolkit",诞生于宾夕法尼亚大学,以研究和教学为目的而生,因此也特别适合入门学习。NLTK虽然主要面向英文,但是它的很多NLP模型或者模块是语言无关的,因此如果某种语言有了初步的Tokenization或者分词,NLTK的很多工具包是可以复用的。NLTK收集了大量公开数据集[...]
1
...
12
13
14
15
16
...
29
关注公众号,每天学一个AI知识
分类
默认分类
PyTorch 电子书
Python 电子书
推荐系统电子书
计算机视觉电子书
机器学习电子书
强化学习电子书
PyTorch 教程
AI数学电子书
数据结构与算法电子书
人工智能实习与内推
网站公告
图神经网络电子书
飞燕AI训练营
多智能体与无人机
科研论文
大模型电子书
创业杂谈
PyTorch GPU 并行训练
PyTorch Lightning 使用介绍
最新文章
一场因代做项目引发的官司与纠纷
最新网站公告:关于本站的资源下载方式的改变
PyTorch Softmax函数的实现
Pytorch Embedding的本质理解:查找表
Positional Encoding位置编码的作用
飞燕网之广告说明
深度开发者们对显卡驱动的困惑
cuDNN的介绍
torch.log()函数的使用介绍
面试天下网 :专注于深度学习和大模型面试分享
《ChatGPT原理与实战》高清完整PDF版 下载
网站公告:深度学习公开课
《ChatGPT原理与架构》高清完整PDF版 下载
《实战AI大模型》高清完整PDF版 下载
《大模型RAG实战》高清完整PDF版 下载
热门文章
《 百面深度学习》高清完整PDF版 下载
《深度学习推荐系统》全彩版 高清完整PDF版 下载
《Python深度学习:基于PyTorch》中文版 高清完整PDF版 下载
技术交流群-成员昵称-参考列表
《机器学习的数学》高清完整PDF版 下载
《优美的数学思维(原书第2版)》高清完整PDF版 下载
Keras怎么读?解读Keras英文发音
《数学之美 第三版》高清完整PDF版 下载
最新评论
瑾年
:
非常好的书
阿瑶
:
求书
xxxx
:
谢谢
安全科学家
:
请赐教,谢谢
matt
:
非常值得推荐
晒衣你
:
好书
半缘君
:
个人学习用,谢谢支持
xiaobai
:
大佬,可以麻烦您发我[...]
bodong
:
感谢分享
Ruozi
:
非常好的书
友情链接