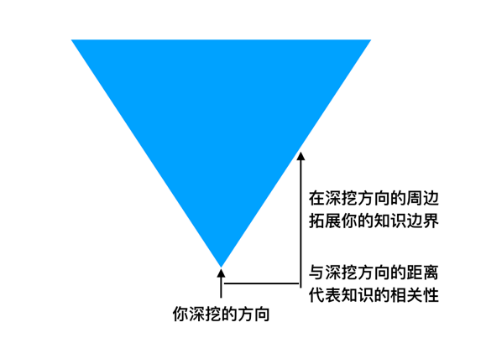
人类的需求一定有明确需求和不明确需求两大类,搜索代表的是明确的需求,而个性化代表的是不明确需求,所以只要人类有获取信息的需要,个性化推荐一定会伴随人类的发展,一直持续下去。虽然推荐算法不会消亡,但是一定会遇到挑战和变数。推荐算法工程师最大的危机来自于云计算及 AI 的发展,越来越多的云计算公司将 AI 作为云服务的基础能力 (包括推荐能力) 封装起[...]
大家都知道互联网技术方向的职业发展一般有三条道路:第一条是一直做技术成为技术专家;第二条是转管理方向;第三条是做到一定程度转行到周边方向,如产品、项目经理等。在国内,多少对年纪大了的技术人员有一定的偏见,认为年纪大了干不动了,所以大家都愿意往管理方向发展。其实,在国外做技术是非常自信和自豪的事情,听说在 Google 技术人员的地位非常高,只有技术[...]
计算机“看”不到图像的内容,对它而言,图像是巨大的数值,即数值矩阵,矩阵元素表示像素的颜色信息。例如,某幅图像分群率为1280 x 720,表示图像有1280 x 720个像素点,则存储为1280 x 720的矩阵。对于彩色图像,每个像素点有红、绿、蓝( RGB)3个颜色的通道值,每个值在0(黑)到255(白)之间。对于灰度图像,每个像素点有亮度1[...]